2 horsemen? What happened to 4? Well 2 of them tend to visit quite frequently in being the underlying cause of Incidents. Change and Scale. The other 2 I’m yet to settle on, but I reckon one should be security. Security seldom visits but when she does she doesn’t just hit hard and run like the other two, she brings the rain. Change on the other hand visits frequently and should be high on your list of things to noodle over if you want to have teams running services in the cloud. With that in mind, let’s talk about my time with Atlassian and the varying flavours of dealing with it.

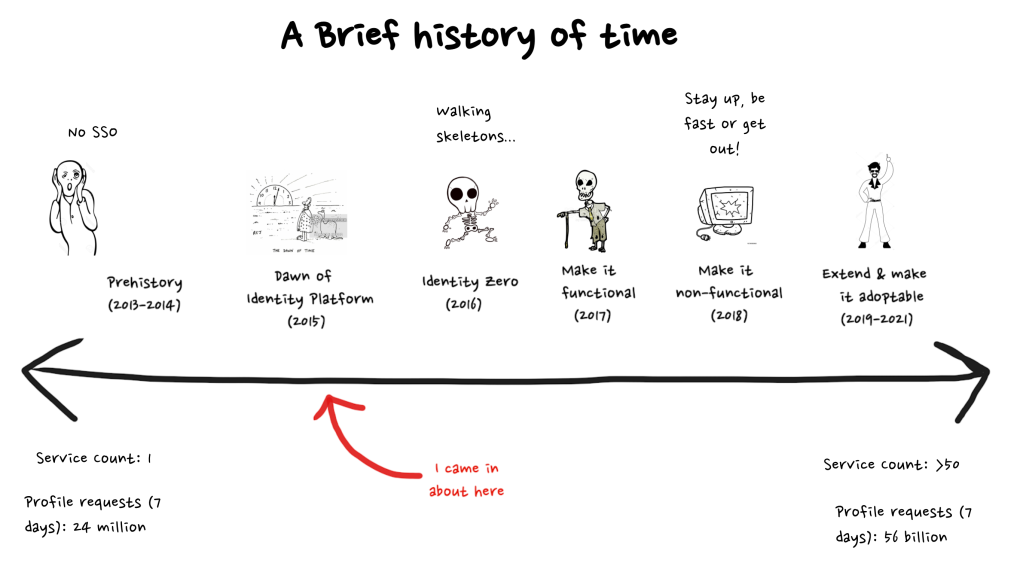
Once upon a time the job of a Software Engineer was to write software. However that simple definition started to blur around the time Agile found its footing and started talking about cross-functional teams. However, the real death knell came with the DevOps movement and true vertically integrated delivery from commit through to end customer with no other parties involved. At some point we’ll have to revisit what we call Software Engineers to better reflect that they now are effectively service providers but thats not what we’re here to discuss today. When I joined Atlassian it was about the time it started to shift from having teams that dealt with operations, to teams that were embedded to help support teams in running services and aspirations toward You-Build-It-You-Run-It.
With the big lift and shift to a constellation of tenantless microservices in cloud, Identity was forced to go the whole hog early on and fully embrace a You-Build-It-You-Run-It model. Most other teams came later or are still on their journey to decompose and make use of a Site Reliability Engineering model. Any approach to roll out services with minimal change related incidents requires a combination of many things; technology/tooling, process and culture.
There are several ways you can approach this with your team:
- Change Advisory Boards – If you are doing this (or subject to it), stop; grab a cup of coffee and go read Accelerate. One of the best treatises on the subject of software team performance I’ve read that found “approval by an external body (such as a manager or CAB) simply doesn’t work to increase the stability of production systems, measured by the time to restore service and change fail rate. However, it certainly slows things down. It is, in fact, worse than having no change approval process at all.”
- Chopper – A process in Atlassian for teams mostly working on monolithic systems with many changes committed to a single system that need to be bundled up and rolled out. It is a centralised process where changes are brought to the Chopper meeting with a panel of experts on the system, they’re reviewed and a “pilot” is nominated to shepherd the batch of changes through. It sounds like a CAB but it is different. Primarily, the panel are fellow developers working on the systems with a large degree of expertise (i.e. it is an internal review by experts, not an external one). It is a great system when you need to coordinate a large number of changes through a single deployment pipeline or when you don’t have enough expertise in your teams to go for something more autonomous.
- The Bar – Is what we went with in Identity. With microservices owned by the team, there is no panel of experts outside the team for the systems they work on. We had the knowledge within the department, and for the most part in teams. What we didn’t have was
- the sense of empowerment and accountability – delivery pressure, lack of clarity on expectations to push back on “just ship it” were all cited as reasons for taking risks that contributed to incidents
- clarity on when/if there had been a review of the plan to manage the change risk; moreover lack of clarity on who is signing off on that work and when – no one should mark their own homework.
- awareness of tools / patterns / solutions to common gotchas – Also varying degrees of inconsistent application of tools / standards / patterns (e.g. “fast five” – an approach for making changes to schema in isolation from code)
So which way do you go? Well obviously not the first. But if you’ve a need to coordinate a high volume stream of changes into a monolith from many teams or your teams don’t yet have the expertise to write and operationalise services themselves go Chopper. However if your teams know what to do, but you have issues on empowerment and accountability… go The Bar.
What is The Bar?
The Bar is made of up three pieces:
- The Manifesto – a statement around expectations to be applied on every change. It is above all else a statement of empowerment and accountability for the engineer making the change and the one reviewing it.
- The Process – the agreed upon means by which The Manifesto is enforced – at the core is peer review of the thinking and work that goes into a change. This includes consideration of “The Standards”- practices are are strongly recommended but may not be applied due to lack of awareness or encouragement.
- The Standards – A set of patterns and tools that represent best practice and should apply to all teams and services. For example: When using progressive rollout, all services should be monitoring for elevated rates of 5xx and 4xx errors on the new stack. It is deliberately not exhaustive, but lists important tools/patterns teams should follow that may not yet be second nature to everyone in the team.
The Manifesto
I will not merge / promote / release until it meets The Bar. At a minimum that means –
We are confident:
- we can detect breaking changes through automated means before they go out to production
- we have automated means to measure that things are working as expected and will be alerted when they’re not working as expected in staging and production
- if we release a breaking change, the impact would be mitigated within SLO and without causing a major incident
- this change is resilient to failures in its dependencies
- we understand the load expectations on our service & its dependencies and the change in load can be safely managed
You-Build-It-You-Track-It – for any change you are accountable for ensuring it passes The Bar; you have full credibility for the work as well as full responsible for safely shepherding it to production.
Approving-Is-Co-Authoring – For any change you approve, you are responsible for understanding the change and agreeing that they pass The Bar; you should consider the change co-authored by you.
The Manifesto is key and is basically an agreed definition of done for operational concerns that give engineers agency to question and push back on shipping if they lack confidence and wouldn’t put their name to the decision to ship it.
The Process:
We debated if there should be a process for simple changes and one for complex / bigger changes. Rather than then push the conversation to debating if a change is simple or complex (when in reality any change is a on a spectrum that requires application of judgement); we opted for a single process.
At its core is the application of judgement from the engineer owning the issue to ensure The Bar is met, peer review by one member of the team who shares equal accountability and a supporting list of best practices we expect teams to explicitly consider.
- The process…
- Every issue starts …
- “In-Analysis”
- planning what needs to be delivered to meet The Manifesto outlined above with a peer
- which of the practices below apply to this particular issue
- documenting this on the issue
- “In-Analysis”
- For every change that will go out to production (eg. a PR, or feature flag change)
- A reviewer will check the documentation, created above, and make sure all relevant items are considered and any additional items required to meet the manifesto and implemented in the change before it can go to production. Discussion documented on the PR (or appropriate area for non PR based changes)
- A reviewer will check the documentation, created above, and make sure all relevant items are considered and any additional items required to meet the manifesto and implemented in the change before it can go to production. Discussion documented on the PR (or appropriate area for non PR based changes)
- Every issue starts …
Expected outcomes
- All changes have a kick-off with a peer reviewer to assess risk and form mitigations
- No changes will make it through to prod without a reviewer assessing that the mitigations are in place
The beauty of this process is its flexibility, teams can tailor other checkpoints in how they like. Some teams augment their design reviews with specific questions relevant to known risk areas and problems. Some have automated rules triggered on raising a PR that will detect specific changes and require responses to specific question. They’re all different, but they all define how their process works and the checkpoints to ensure the Manifesto of the bar is upheld. Between the flexibility in the process and the accountability from the Manifesto The Bar ensures teams create processes that will deliver on the outcome, rather than the output of following something more prescriptive and hence not enabling them to apply their judgement (the Bar is there to support good judgement, not get in the way of it).
The Standards
I won’t paste them verbatim here because they really depend on where your team are at and some of them involve adoption of Atlassian tech but to give you a flavour:
- Progressive rollout with anomaly detection and automated rollback – have the least amount of impact we can have and detect it as early as possible and automate the response – 99.99% only allows for 4 minutes of disruption on a month, you can’t do that if you’re detect response loop involves humans and a large percentage of users.
- Fast 5 for data changes – basically rollout new code to deal with schema change, roll out the schema change, roll out the new behaviour change, remove the old data, code and behaviour. The intent here is to have a safe tested way of running multiple versions of data, code and behaviour in parallel (because you may need to revert back to a previous state at any point until the entire new state is validated.
- Safe rollbacks up to 48 hours – even with the above and with progressive rollout we know some problems aren’t detect right away and the fastest way to resolve an incident is often to auto-rollback to a previous version if a new one was recently deployed. Endeavour to make this an unquestionably safe operation.
- Consistent two-way feature flags – feature flags are progressive, often eventually consistent and may flip back at any time. Do not assume flags progress only ever in one direction, even if you plan to use it that way your underlying feature flag service may fail and revert to the default state.
- Announce changes, have appropriate docs and plans, ensure support staff know what is happening so they can alert on the unexpected (and not look like numpties if something new goes out).
So how are we doing…
We had our quarterly TechOps review where we look at operations and incident trends. Major incidents due to change have continued to trend down throughout the year (and TBH we’re in very low numbers). Teams aren’t stifled by rubber stamping process and check boxing that doesn’t apply to their context and they feel empowered because The Bar doesn’t prescribe what to do, it just provides the agency for teams to do the right thing.